
Balance between scalability and complexity
Hey guys. This is my perspective based on my engineering experience.
I. Start small
We start from a scratch, building a totally new project. At this milestone, we face many challenges. We decide the architecture based on whether we are big company and we have a lot of money or we are just a small startup.
As a big company we have a lot of money so we have many teams who have diverse skills. We’re also sure that this new project will have more than 50% of success according to our business and the leader’s vision. That is good for us to start building the scalable project. We can start with a distributed system, especially the microservices based on container technology. Or we start with a serverless architecture. This is perfect for us if our company has the perfect condition like this.
However, if our company is small startup. We have less money with small team or even only one developer and we are not so sure about the success of the business. Because we’re startup, right?. So we should start small, making a demo version and trying to get the feedback from end users. In this case, we should build the monolith project. Why? Because it’s better for development speed, keep low cost, starting with a small team that’s enough. Even our business failed, we start to build another project. The failure is inevitable for startup. And if the project is not in the right direction, we make change easily with monolith.
Time flies, and luckily our business grow, we need to scale the project to serve million of users. This time, we scale the monolith to distributed architecture. Need to say that each architecture has pros and cons. The distributed system is high availability and scalability but also high complexity. We need many teams and do more things to manage this. This is hard for testing and keep the business logic centralized. So it’s hard for management. However, the availability is more crucial for us. I just want to say, either monolith or distributed system both has pros and cons. We shouldn’t think that distributed system is perfect.
II. We need to scale
The technical lead needs to consider to transform the monolith to distributed system and we do this slowly and carefully. I’m not saying that the monolith can not be a distributed system. We can build multiple services like this.
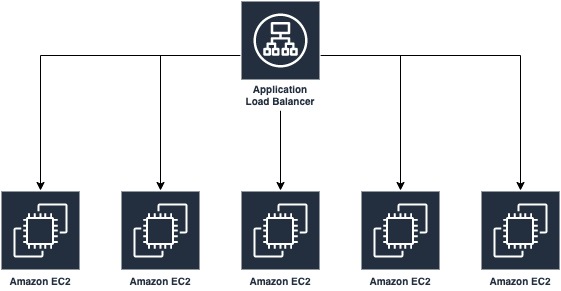
But the problem is that for whatever reason the entire system has to be deployed together. So it can not keep the promises of SOA.
We separate the project to components. We need even the solution architect who understand the business logic and have a good domain driven design.
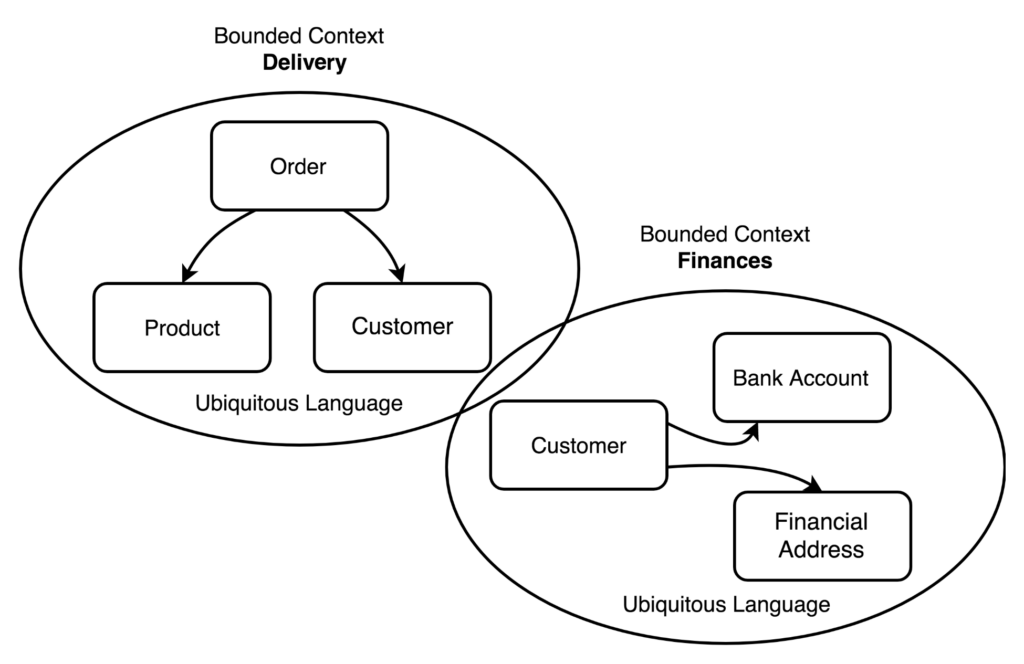
Nowaday, we use the cloud-based infrastructure. But if we are using the on-premises we need to migrate the system to cloud. We choose AWS because the team has good skills of this Cloud.
Now we have a single code base, we need to host this code somewhere using a compute service. AWS provides many compute services.
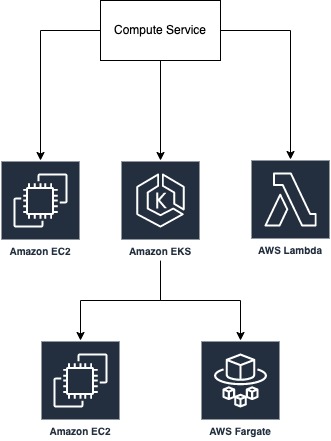
EC2
We normally start with EC2 to host the website. This is the default option when we think about the compute service. Because EC2 is the first one that AWS provided as the compute service. EC2 can absolutely do good job. However, it doesn’t mean that we should stop at this solution. There are many potential solutions to a problem, we should weigh up them all and see which one is a good fit. AWS provides two other compute services to make a distributed system, EKS and Lambda.
EKS
By using EKS, we can host our code on Fargate which is a serverless compute plaform for container. Or we can choose EC2, it depends. There are many advantages of modern serverless system such as saving cost and scalability. If our teams have the skills about container technology we can pick this one. Logs and metricts go to CloudWatch, high efficiency.
Lambda
Last but not least, Lambda is the next compute option for serverless as well as distributed system. Lambda is cloud native, scale up and down automatically that we don’t need to care about. Lambda built on the microVM and it will shutdown on its own after a period of time. We pay for what we use, so It saves the cost. Thus, it’s a good fit for startups because they don’t have a lot of traffics at the beginning, lambda saves their server’s cost. Otherwise, we need to clarify if the service which is built on lambda is a permanent service. If that is the case, lambda is insufficient. It will increase the cost even more than EC2. it also make extra network communication. We have to spend for these costs and latency. If we are a business which has already grown, we should focus on the specific unit of work. Like I mentioned, serverless is good at high scale, we should use it in case by case only. Avoid migrate the whole architecture to serverless. The right case for serverless is for less frequent unit of work and excellent scalability at peak points.
III. Challenges
Like I said that if we are familiar with container technology we can pick EKS with Fargate. So why don’t we pick Lambda instead. Because we want to save the development time. We have the source code already. We put them in containers and deploy to the EKS cluster. Off course, we need a team or someone who have container skills such as Docker, Kubernetes, EKS, ECR, ECS etc. If we use lambda, we need to develop according to lambda way. We put more time to write code but saving devops time and cost. It depends. But if that is a new startup and we put high priority on saving cost because we don’t have a lot of traffics, I recommend to develop lambda function. But cost saving is not right when the business has been grown. We should re-architect at this time if want to save cost. High and permanent traffics is not the use case for serverless. The data delivery though internet charges us a lot of money. For example:
- The event bus.
- Reading s3 bucket many times because of separated services.
- NAT Gateway.
- Architecture is more complicated. Need more resources to do, more engineer teams to manage.
- Many more potential issues.
EKS with Fargate has same case usage as lambda.
When we transform the monolith to distributed system, especially microservices we encounter a lot of challenges:
- Domain Driven Design. We must have someone who understand deeply the business domain and transform them to technical services.
- Splitting component but make sure the rests working normally. We know that when we transform monolith to microservices we do this step by step, service by service.
- The complexity of distributed domain makes it difficult to handle failures and hard for debugging.
- For monolith, we deal with the whole source code, easier to find the logic in same centralized place. But distributed system, the complexity moved to the interaction between services. It’s hard for testing and chasing the issues.
- Hard to follow the information flow. Need documents updated regularly.
- Replicate the production environment locally become super difficult if don’t want to say it’s impossible. We might build a local cluster for testing but not totally like production environment.
- No conventions. We follow the microservices patterns. But it’s hard to implement these ones. Many decisions the team has to make. We have many diagrams to transfer the knowledge among the teams and members. Can not get the flow easily be simply reading code. Things become messy.
IV. Balance
In facts, I use both monolith on ec2, microservices using container technology EKS as well as serverless by lambda. I need to balance between the complexity and availability. So I keep monolith whenever it’s working good and meet the business requirement. When the the performance issue comes I optimise the monolith or separate the microservices following the horizontal scaling. Trying to scale to keep good availability and limit the growth of complexity.
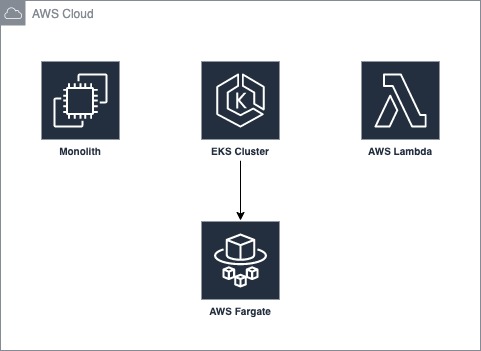
We code and build architecture that is we are solving customer’s problems. We want to keep our solution available overtime. Scalability is as crucial as Maintainability. We want to reduce the complexity to save cost, easily manage and evolve. Thus, we need to get balance.
Bonus: Let’s see how Prime Video reduce costs from distributed serverless to monolith.